Development of the COVID Corpus Website
In a project that delved into the wealth of COVID-related academic literature, I had the unique opportunity to apply my machine learning skills to make sense of complex datasets. The project, a part of my final year under the guidance of my project supervisor, was a cornerstone in my exploration of natural language processing (NLP) and its applications in the real world.
Preview
Highlight
-
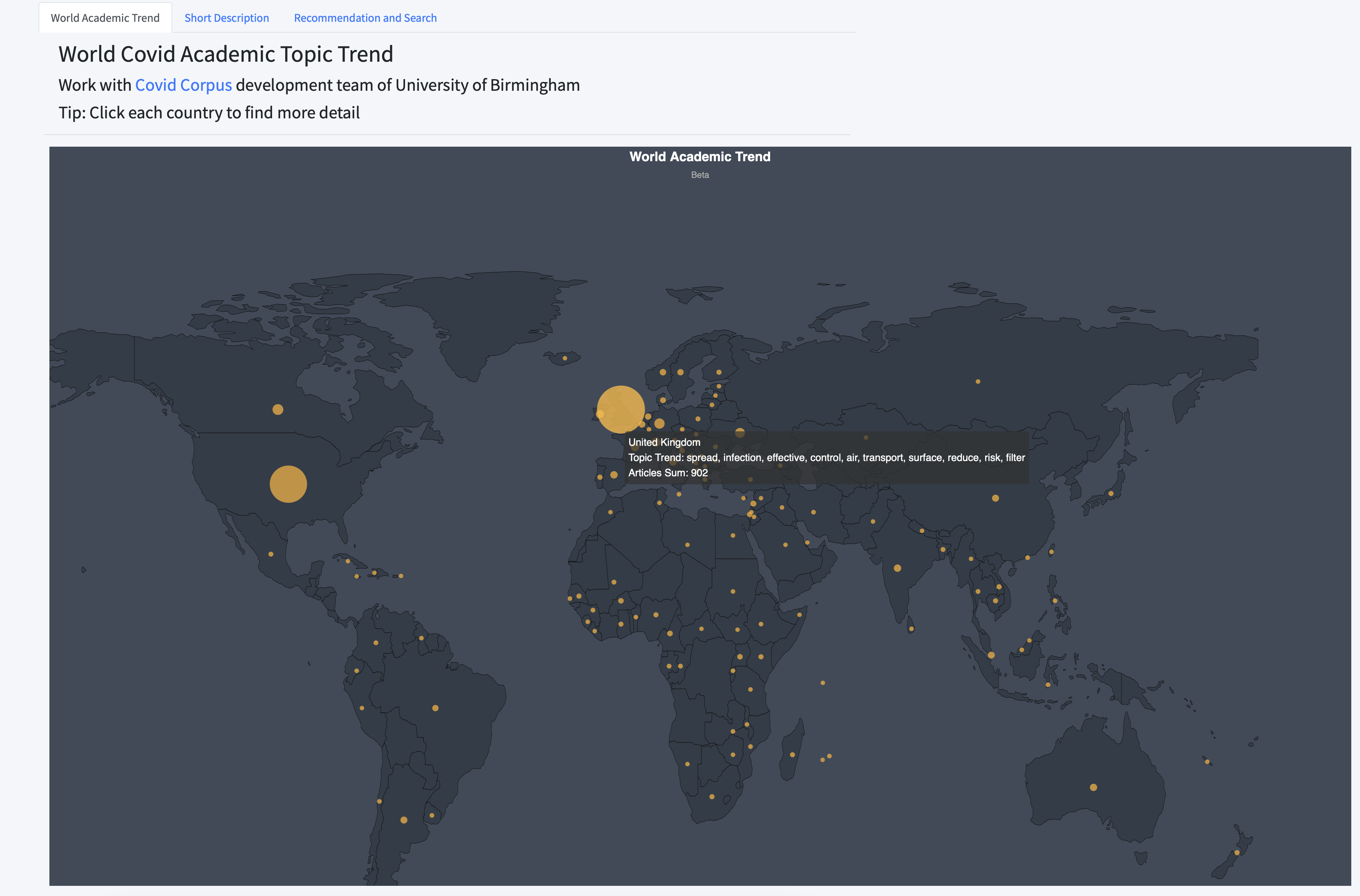
Deployed NLP functions on a Django server, providing robust APIs for seamless analysis result retrieval. Spearheaded the NLP module development for the COVID Corpus website using the React framework, working closely with the development team to ensure accurate and effective data visualization.
-
Cleaned and preprocessed COVID-19 research data with NLP pipelines for quality analysis. Applied LDA algorithms for effective topic modelling in large datasets. Implemented BERT-based summarization tools to distill detailed academic texts into brief overviews. Built a recommendation system using TF-IDF and document similarity to improve the ease of finding related research.
Related Work
Data Cleaning and Preprocessing:
The raw data, a vast collection of academic articles and projects concerning COVID, was first subjected to a rigorous cleaning process. Using an NLP pipeline, I filtered out inconsistencies, removed noise, and standardized the text data to prepare it for analysis. This step was crucial, as the quality of the input data directly influences the reliability of the NLP models’ outputs.
Topic Modeling and Summarization:
One of my main tasks was to implement an automated selection and optimization process for Latent Dirichlet Allocation (LDA) models. LDA is a machine learning technique that identifies topics within a large volume of text. By optimizing these models, I was able to categorize articles into topics efficiently, making the vast corpus of research more navigable and understandable.
Additionally, I deployed BERT (Bidirectional Encoder Representations from Transformers), a state-of-the-art deep learning model, to develop an article summarization algorithm. This model was trained to distill lengthy academic content into concise summaries, thus enabling quicker assimilation of key findings and insights.
Recommendation System:
A pivotal part of the project was the creation of a recommendation module. Utilizing techniques like TF-IDF (Term Frequency-Inverse Document Frequency) matching and document similarity, I crafted a system that could suggest related articles to researchers, thereby enhancing their study with relevant literature they might not have otherwise discovered.
Deployment and Front-End Development:
Bringing these NLP functionalities to life, I deployed the code on a Django server, transforming the algorithms into accessible APIs. These APIs were designed to deliver the analysis results effectively for use in front-end applications.
On the front-end, I developed the NLP module using the React framework, ensuring a responsive and user-friendly interface. In collaboration with the development team, we integrated data visualization components to the website, presenting our analysis of the COVID corpus in an interactive and digestible format.
Through this project, I leveraged NLP to bridge the gap between extensive academic research and the need for accessible, synthesized information, thereby contributing to the global understanding of COVID-related studies. This experience underscored the potential of machine learning in enhancing the accessibility and utility of academic literature in times of crisis.
Comments powered by Disqus.