Machine Learning Engineer Internship at Shengqu Games
Unreal Department – Artificial Intelligence Group
From 06-2023 to 12-2023
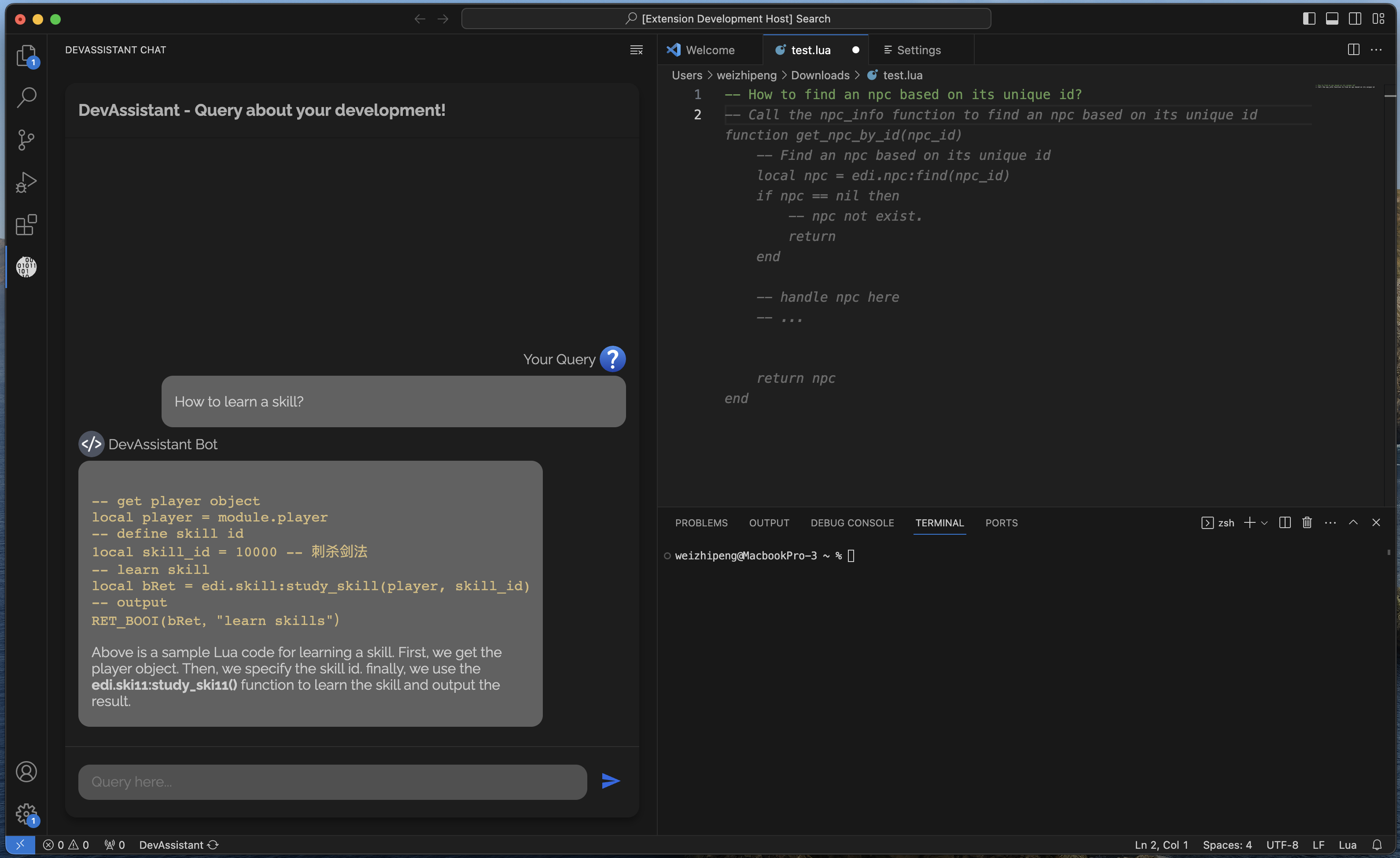
Preview
Left is chat with API document. Right is code complete.
Github Repository
Project: https://github.com/Miraclove/DevAssistant
Highlight
-
Led the development of a 20-billion parameter language model for code completion, using PyTorch. Improved user interaction by fine-tuning the model for instructional chatting.
-
Streamlined the model training process with Accelerate and DeepSpeed in a Linux environment, using four A100 GPUs, and formulated a unique evaluation method to ensure model accuracy.
-
Deployed the model on a high-performance server using VLLM for fast responses.
-
Engineered a Visual Studio Code extension for real-time coding assistance with company API documents, mirroring GitHub Copilot’s functionality, and added a chat feature using the fine-tuning model for user API queries.
Related Work
In my latest tech endeavor during my internship, I focused on harnessing the power of large language models (LLMs) to refine the software development lifecycle. The goal was to leverage the company’s existing API documentation to train an LLM that could assist developers by providing real-time coding suggestions and conversational guidance directly related to the company’s APIs.
Training and Fine-tuning the Language Model:
Utilizing the versatility of PyTorch, I trained a 20B parameter language model, a task that lays the foundation for the model to understand and generate human-like text. This training was specifically aimed at enhancing code completion tasks. Beyond this, I fine-tuned the same model to facilitate an instructional chat, enabling it to understand and respond to queries about the company’s coding protocols.
Data Collection and Preparation:
A significant portion of my work involved curating a dataset composed of Lua code snippets and the relevant API documentation. This data was meticulously cleaned and modified to align with the training requirements of an LLM, ensuring the model could learn effectively from relevant and high-quality examples.
Training Pipeline and Evaluation:
I crafted a training pipeline utilizing the Accelerate and DeepSpeed libraries, designed to streamline and expedite the training process on high-performance computing resources. With four NVIDIA A100 GPUs at my disposal, the training was conducted in a Linux terminal environment, ensuring maximum efficiency and utilization of resources.
To validate the model’s performance, I wrote an evaluation script that measured the accuracy of the model’s output against the API documentation. The “match rate” between the generated code and the documentation served as a quantifiable metric for the model’s efficacy.
Deployment and Integration:
Post-training, I set up an endpoint server to deploy the model. This was powered by VLLM for swift inference, making the AI’s capabilities readily accessible for real-time applications.
To bring this technology directly into the developer’s workflow, I created a Visual Studio Code (VSCode) plugin using TypeScript. This plugin integrates the pre-trained 20B model to offer in-line code completions, akin to GitHub Copilot. Additionally, a sidebar was integrated into the plugin for interactive chat, employing the fine-tuned 20B model to converse with users, effectively providing a virtual coding assistant within the IDE.
Through these efforts, my internship project sought not only to enhance coding productivity but also to enrich the developer experience with AI-powered tools tailored to the company’s specific development ecosystem.
Comments powered by Disqus.