Deep Learning: Ensemble Methods
Here is my Deep Learning Full Tutorial!
Bagging and Boosting
Ensemble learning




Adaptive Boost

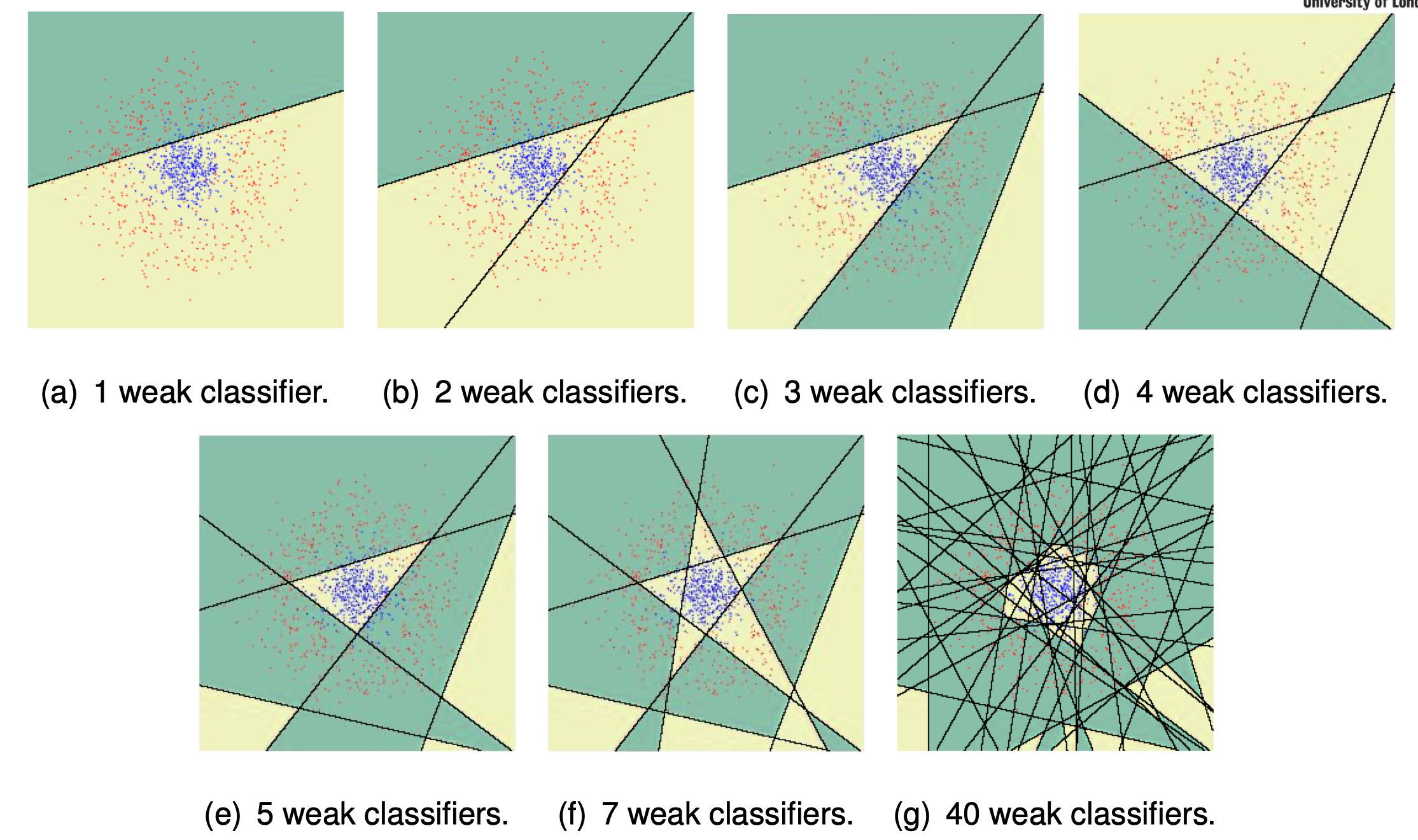
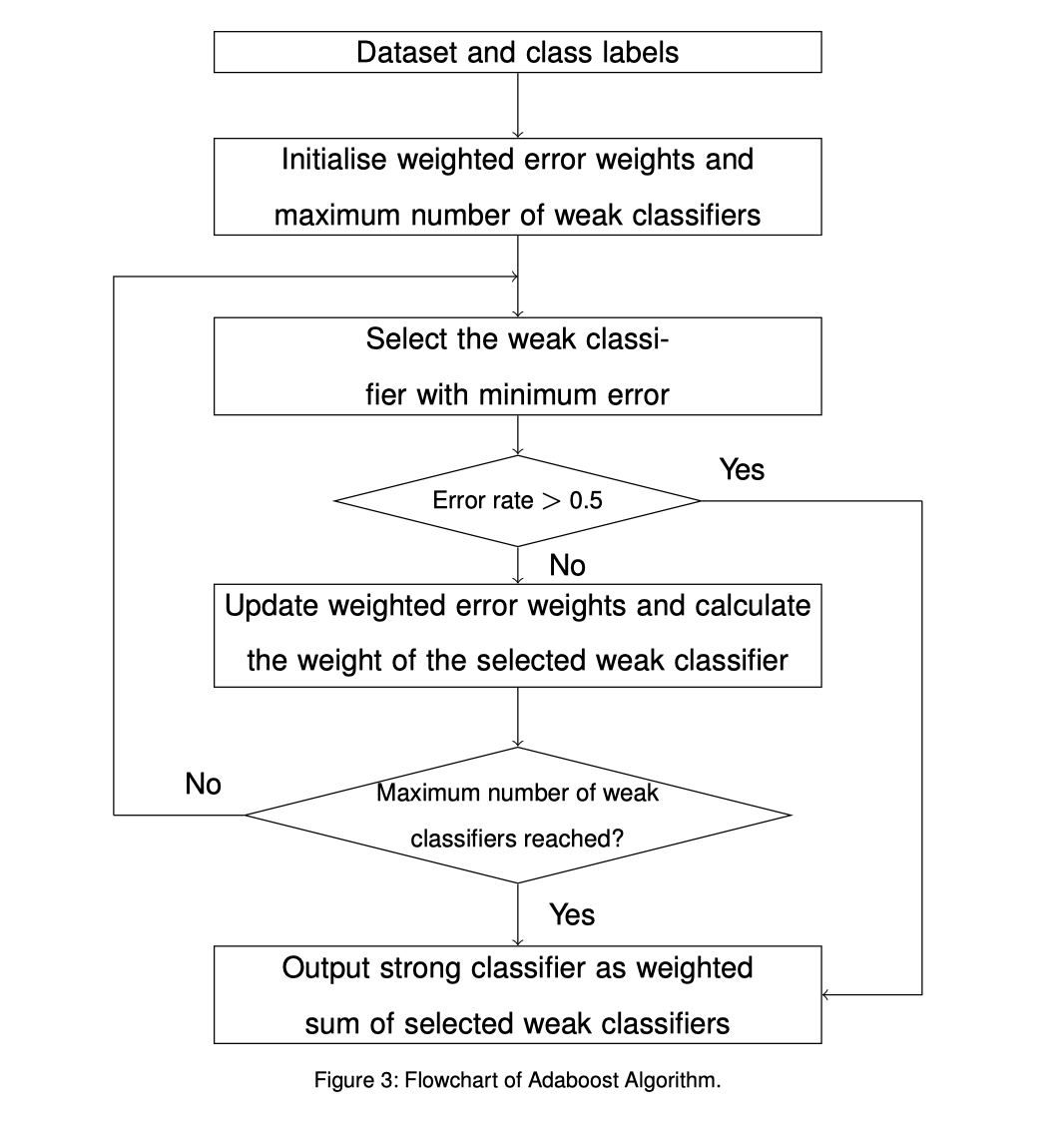

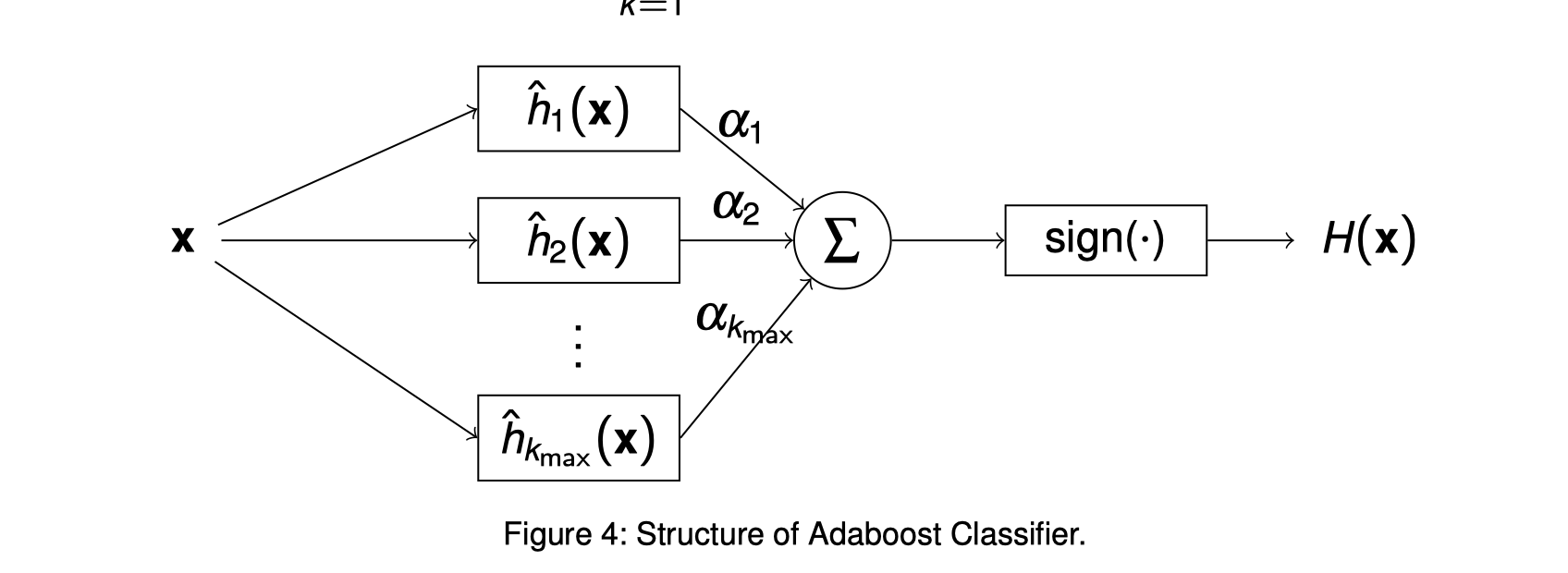
Adaboost - Adaptive Boost Training python code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
import numpy as np
from prettytable import PrettyTable
class_1 = [1,2,3,4,5]
class_2 = [6,7,8,9,10]
h_error = [
[3,4,5],
[6,7,8],
[1,2,9]
]
# Adaboost - Adaptive Boost Training
# -----------------------------------------------------------
item_number = len(class_1) + len(class_2)
w = np.ones(item_number)/item_number
a_list = []
for h_index in range(len(h_error)):
result = []
w_prev = w
error_rate = [sum([w[index - 1] for index in sample]) for sample in h_error]
error_min = np.min(error_rate)
h_argmax = np.argmin(error_rate)
# a = 1/2*ln((1-err_min)/err_min)
a = 0.5*np.log((1-error_min)/error_min)
update_list = []
for index in range(item_number):
if (index+1) in h_error[h_index]:
# w(i)*e^(-a*y*h(x))
update_list.append(w[index]*np.exp(a))
else:
# w(i)*e^(-a*y*h(x))
update_list.append(w[index]*np.exp(-a))
z = sum(update_list)
# w_new(i) = w(i)*e^(-a*y*h(x))/z
w = update_list/z
for index in range(item_number):
result.append([index+1,np.array(error_rate).round(4),round(error_min,4),round(a,4),round(w_prev[index],4),round(update_list[index],4),round(w[index],4)])
# prettytable
# -----------------------------------------------------------
pt = PrettyTable(('i','error rate','error_avgmin','a = 1/2*ln((1-err_min)/err_min)','w(i)', 'w(i)*e^(-a*y*h(x))','w_new(i) = w(i)*e^(-a*y*h(x))/z'))
for row in result: pt.add_row(row)
print(pt)
a_list.append(str(round(a,4))+'h'+str(h_argmax+1))
result = ''
for index in range(len(a_list)):
if index == 0:
result = result + a_list[index]
else:
result = result +' + '+ a_list[index]
print('Final classifier: sgn(',result,')')
Output
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
+----+---------------+--------------+---------------------------------+------+--------------------+---------------------------------+
| i | error rate | error_avgmin | a = 1/2*ln((1-err_min)/err_min) | w(i) | w(i)*e^(-a*y*h(x)) | w_new(i) = w(i)*e^(-a*y*h(x))/z |
+----+---------------+--------------+---------------------------------+------+--------------------+---------------------------------+
| 1 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.0655 | 0.0714 |
| 2 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.0655 | 0.0714 |
| 3 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.1528 | 0.1667 |
| 4 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.1528 | 0.1667 |
| 5 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.1528 | 0.1667 |
| 6 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.0655 | 0.0714 |
| 7 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.0655 | 0.0714 |
| 8 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.0655 | 0.0714 |
| 9 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.0655 | 0.0714 |
| 10 | [0.3 0.3 0.3] | 0.3 | 0.4236 | 0.1 | 0.0655 | 0.0714 |
+----+---------------+--------------+---------------------------------+------+--------------------+---------------------------------+
+----+------------------------+--------------+---------------------------------+--------+--------------------+---------------------------------+
| i | error rate | error_avgmin | a = 1/2*ln((1-err_min)/err_min) | w(i) | w(i)*e^(-a*y*h(x)) | w_new(i) = w(i)*e^(-a*y*h(x))/z |
+----+------------------------+--------------+---------------------------------+--------+--------------------+---------------------------------+
| 1 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.0714 | 0.0373 | 0.0455 |
| 2 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.0714 | 0.0373 | 0.0455 |
| 3 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.1667 | 0.087 | 0.1061 |
| 4 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.1667 | 0.087 | 0.1061 |
| 5 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.1667 | 0.087 | 0.1061 |
| 6 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.0714 | 0.1368 | 0.1667 |
| 7 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.0714 | 0.1368 | 0.1667 |
| 8 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.0714 | 0.1368 | 0.1667 |
| 9 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.0714 | 0.0373 | 0.0455 |
| 10 | [0.5 0.2143 0.2143] | 0.2143 | 0.6496 | 0.0714 | 0.0373 | 0.0455 |
+----+------------------------+--------------+---------------------------------+--------+--------------------+---------------------------------+
+----+------------------------+--------------+---------------------------------+--------+--------------------+---------------------------------+
| i | error rate | error_avgmin | a = 1/2*ln((1-err_min)/err_min) | w(i) | w(i)*e^(-a*y*h(x)) | w_new(i) = w(i)*e^(-a*y*h(x))/z |
+----+------------------------+--------------+---------------------------------+--------+--------------------+---------------------------------+
| 1 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.0455 | 0.1144 | 0.1667 |
| 2 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.0455 | 0.1144 | 0.1667 |
| 3 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.1061 | 0.0421 | 0.0614 |
| 4 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.1061 | 0.0421 | 0.0614 |
| 5 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.1061 | 0.0421 | 0.0614 |
| 6 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.1667 | 0.0662 | 0.0965 |
| 7 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.1667 | 0.0662 | 0.0965 |
| 8 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.1667 | 0.0662 | 0.0965 |
| 9 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.0455 | 0.1144 | 0.1667 |
| 10 | [0.3182 0.5 0.1364] | 0.1364 | 0.9229 | 0.0455 | 0.0181 | 0.0263 |
+----+------------------------+--------------+---------------------------------+--------+--------------------+---------------------------------+
Final classifier: sgn( 0.4236h1 + 0.6496h2 + 0.9229h3 )
Stacked generalization

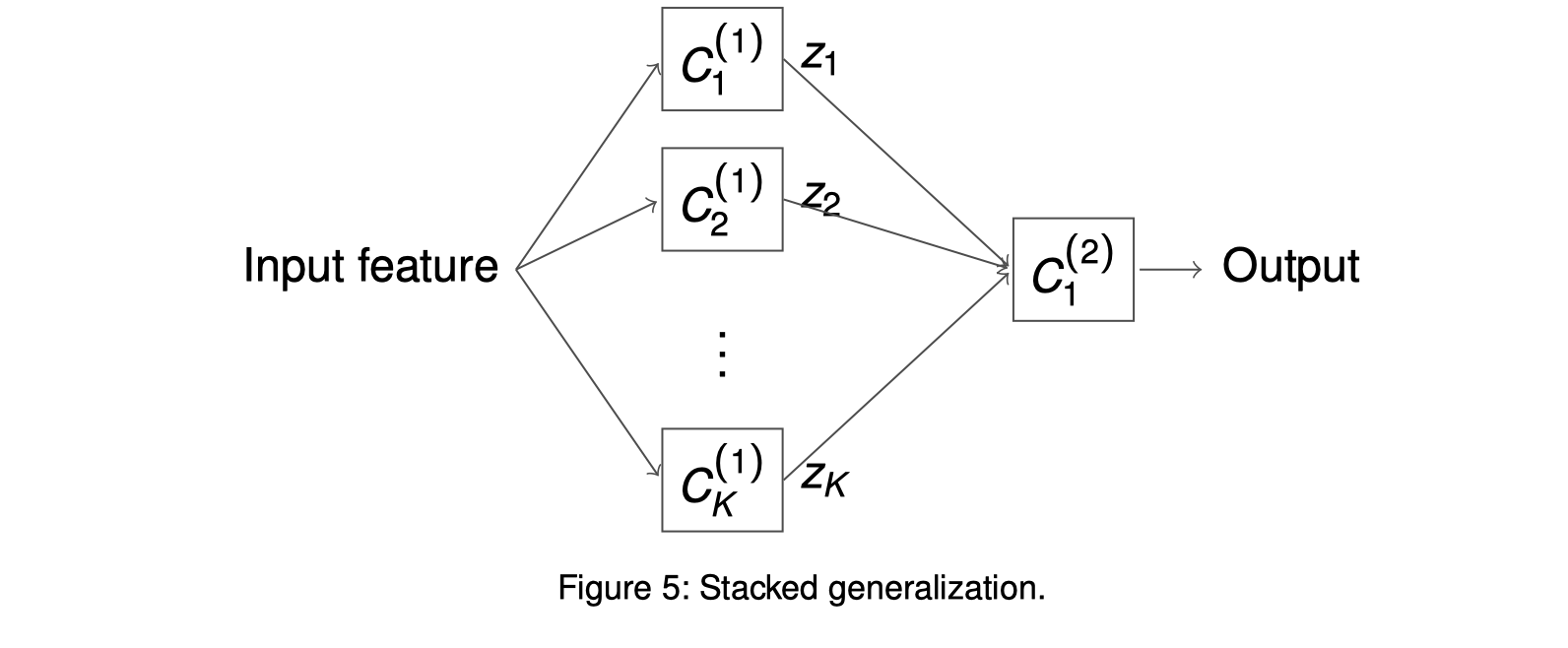
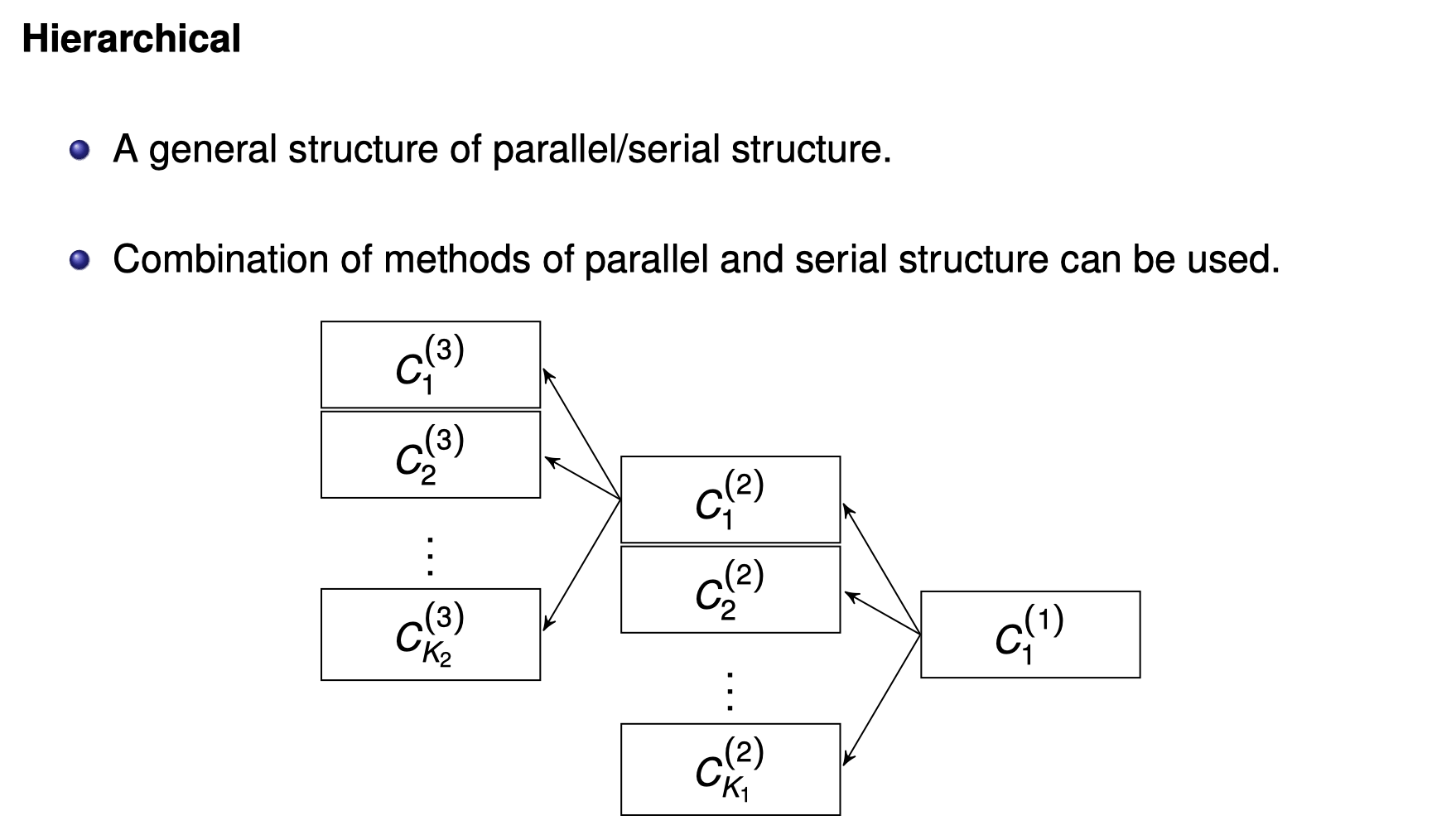
Structure of ensemble classifiers

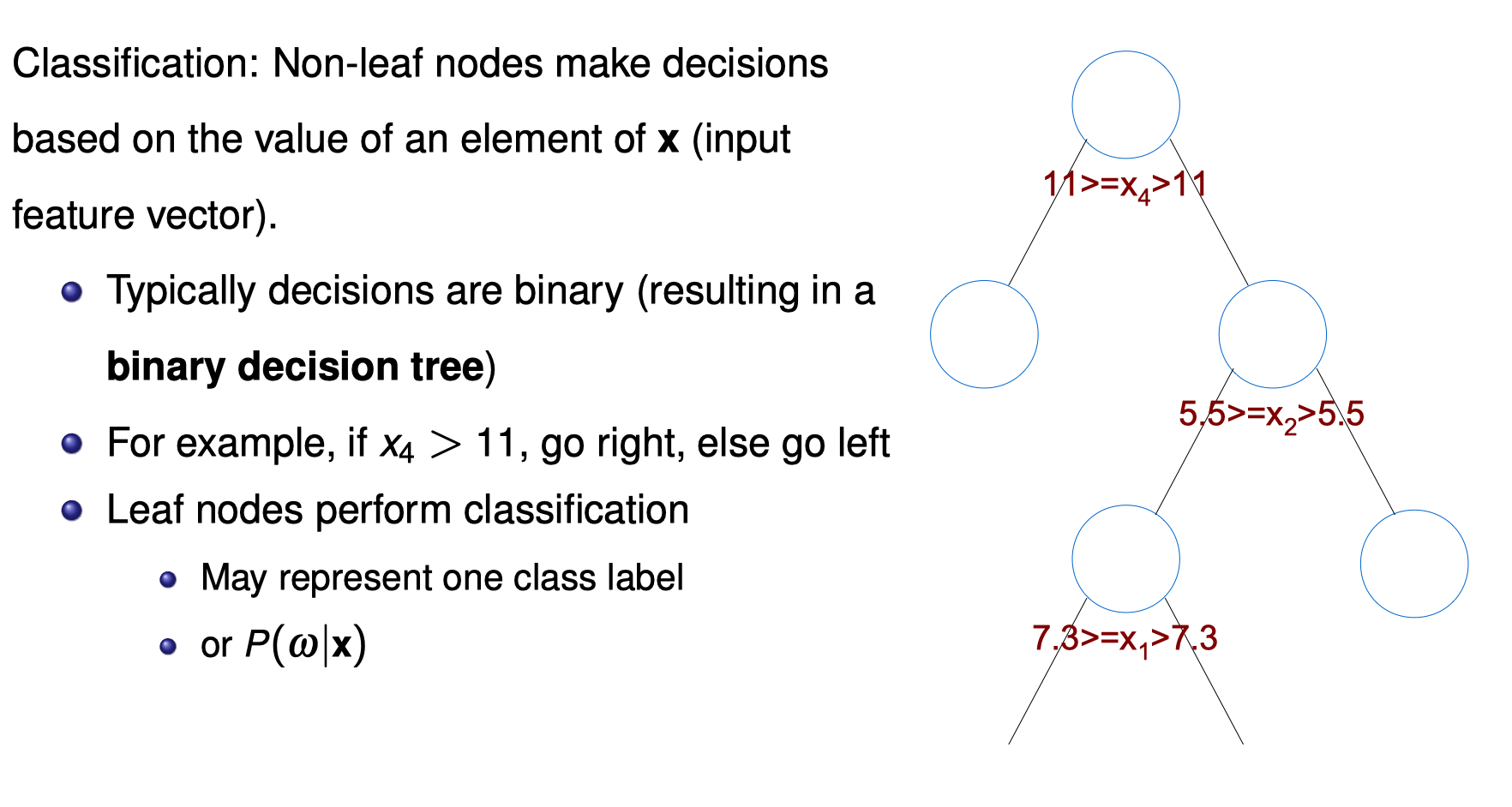
Decision Trees





Entropy python code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
def entropy_impurity(p):
inp = 0
for i in p:
if i == 0:
inp += 0
else:
inp += - i * np.log2(i)
return inp
def drop_impurity(p, p2):
allp = entropy_impurity(p)
sump = 0
for i in range(len(p2)):
sump += -(p[i] * entropy_impurity(p2[i]))
allp += sump
return allp
p2 = np.array([[0 / 6, 6 / 6], [2 / 8, 6 / 8]])
data = np.array([[8 / 14], [6 / 14]])
print(entropy_impurity(data))
print(drop_impurity(data, p2))
Output
1
2
[0.98522814]
[0.63753751]
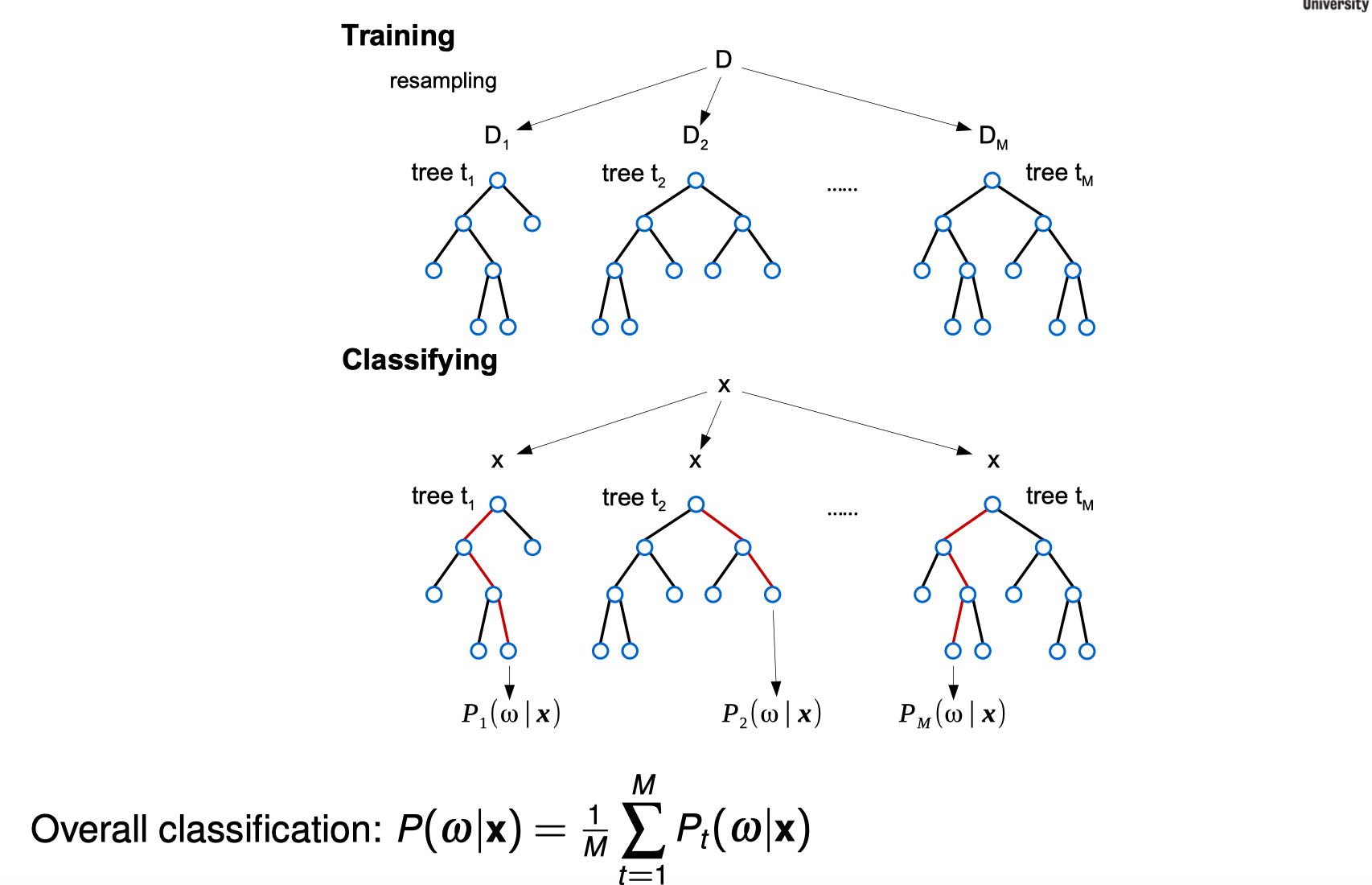
Bagging Decision Trees
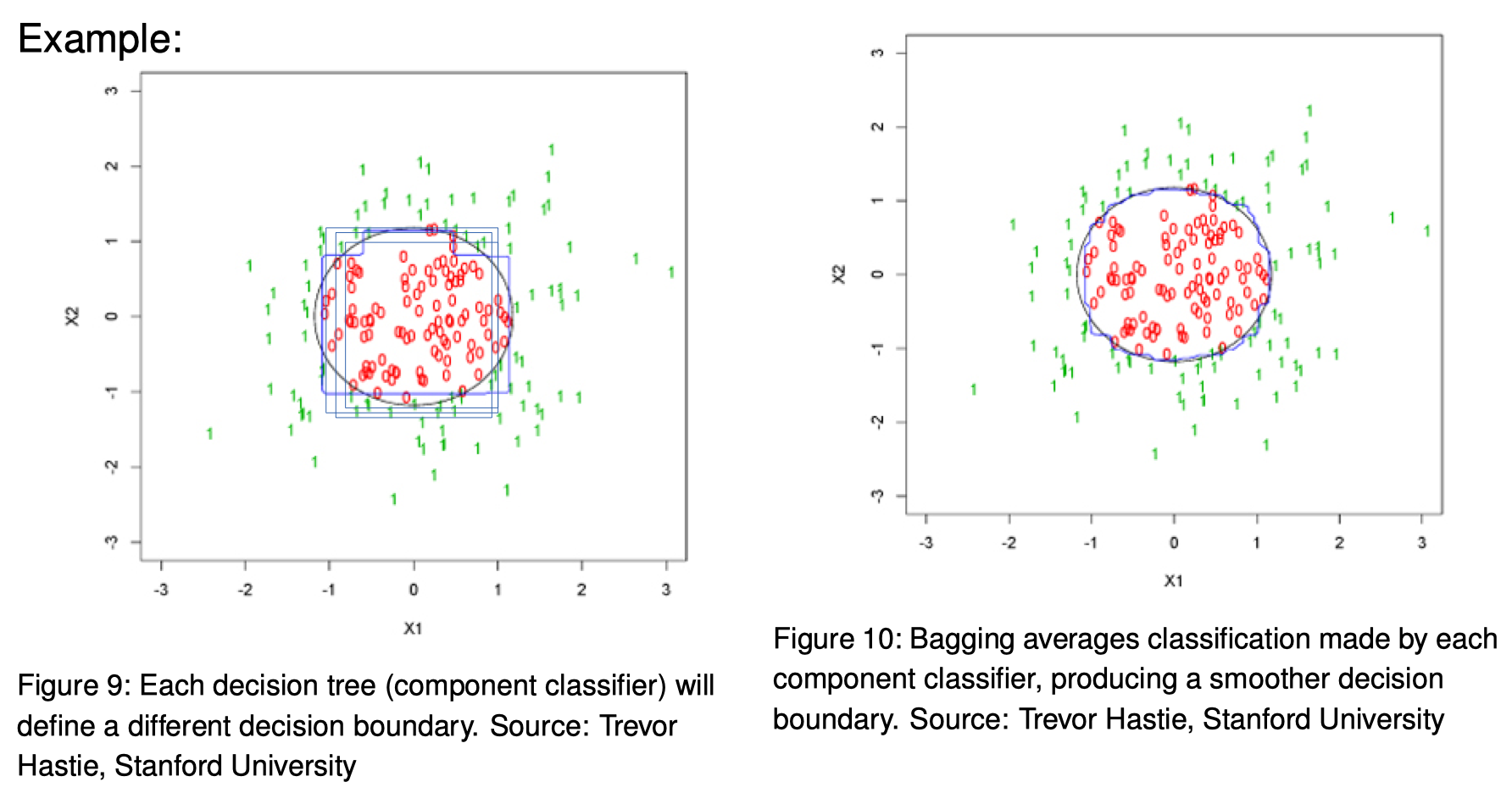
Random Forests



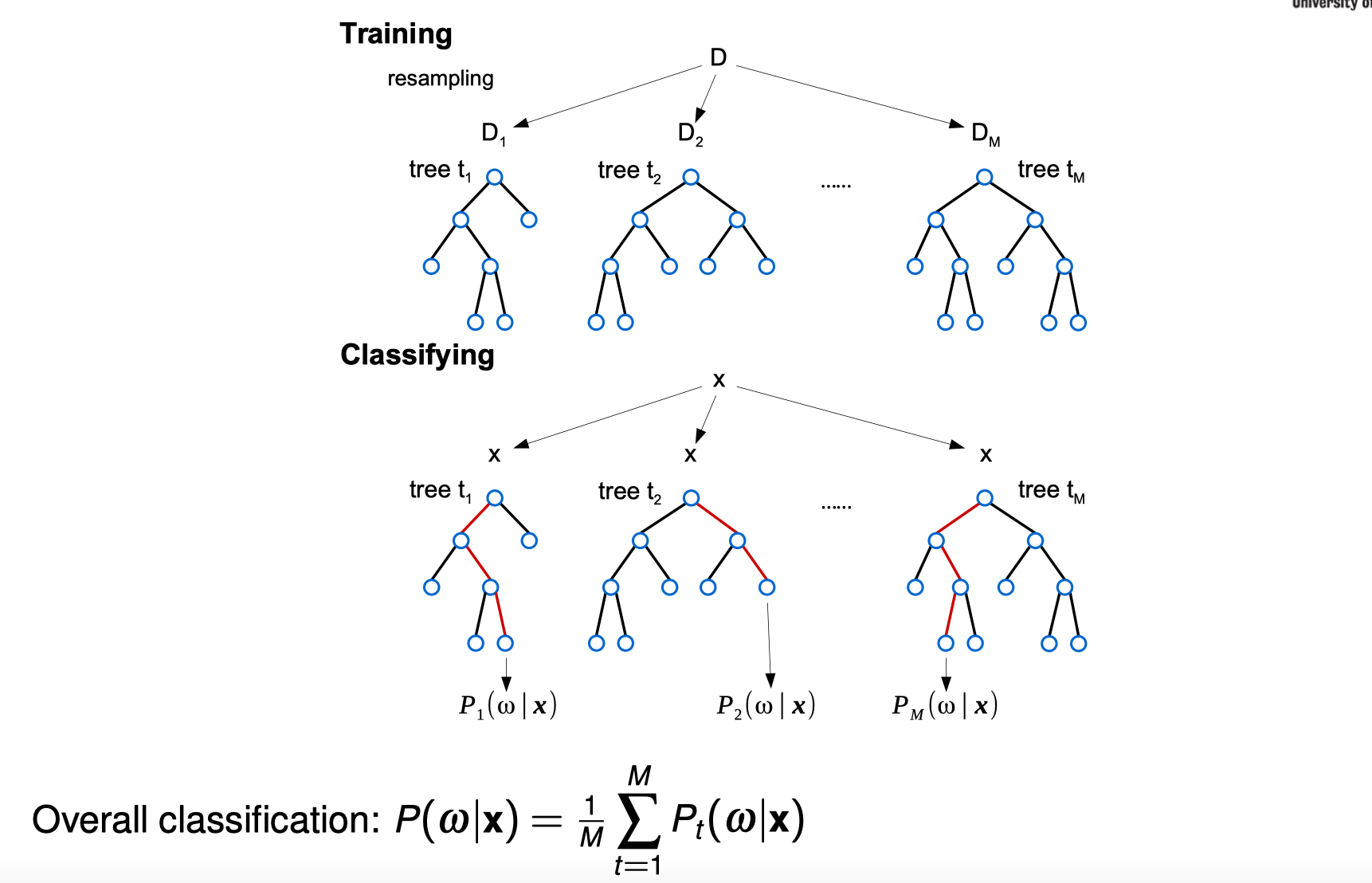
Fast (scalable), Accurate, Simple to implement, Popular
Comments powered by Disqus.